
18 апреля 2017
Как скачать сайт
Super Admin
7012
Сегодня мы будем учиться скачивать сайт целиком. Точнее не весь сайт, а его front end (хотя, в контексте скачивания лендингов или транзиток - это именно то, что нам нужно).
Тема не новая, понятное дело и способов - тьма. Но, в любом случае, очень много людей не знают, как это делать (или просто не умеют пользоваться гуглом), поэтому постараемся пошагово рассказать, что да как. Сразу оговорочка: мы все эти методы не поддерживаем (но это не точно), закон об авторском праве тоже эти дела не приветствует, так что материал публикуется исключительно для ознакомительных целей.
Всё, ответственность с себя сняли. Поехали ;-)
Настройка wget под Windows
В первую очередь, нам необходимо скачать актуальную версию wget.
Теперь мы идём в "Program Files", создаём папку "wget" и выгружаем в неё содержимое скачанного архива:
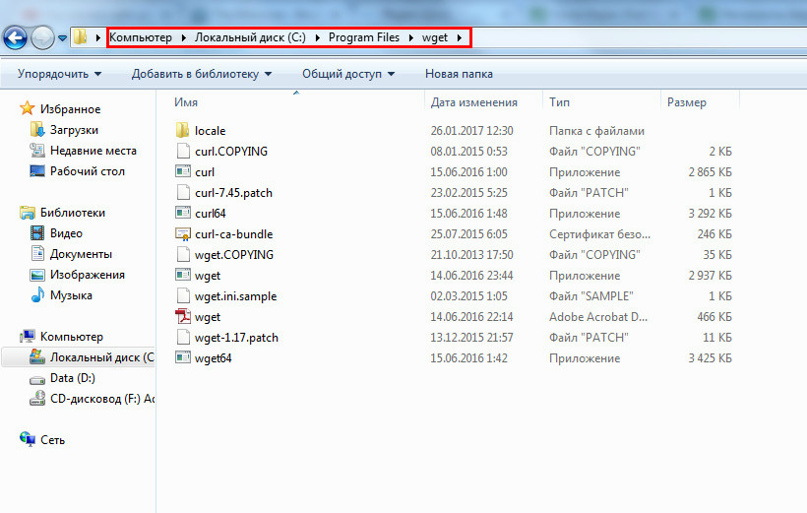
Далее, правой кнопкой мыши по ярлыку "мой компьютер" и заходим в свойства >> дополнительные параметры системы >> переменные среды:
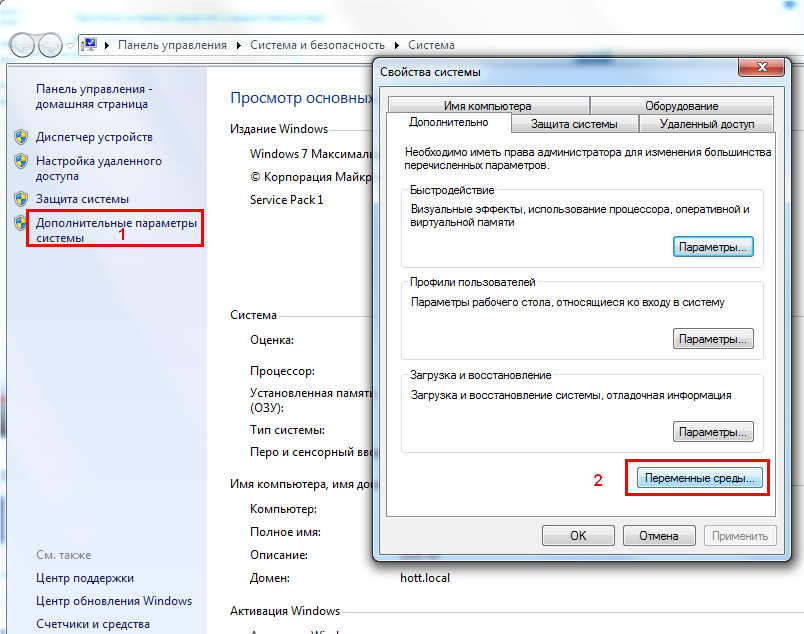
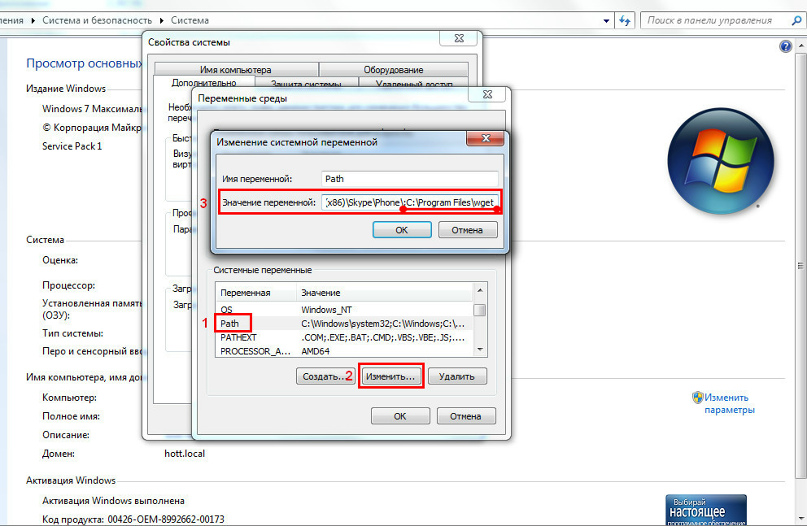
Открывается окно с переменными, находим "Path", жмём "изменить", в конце значения переменной просто добавляем ;C:\Program Files\wget и везде тыкаем "ок"
Запускаем консоль
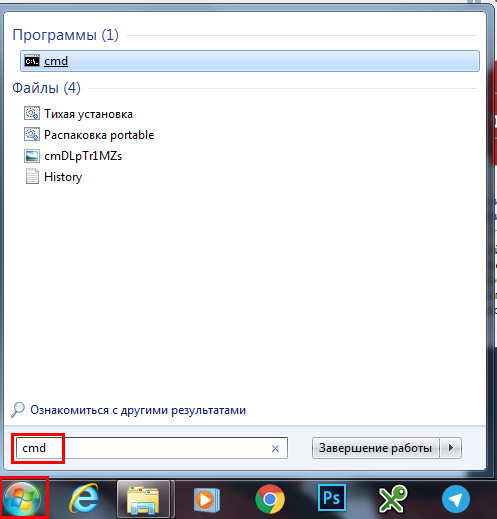
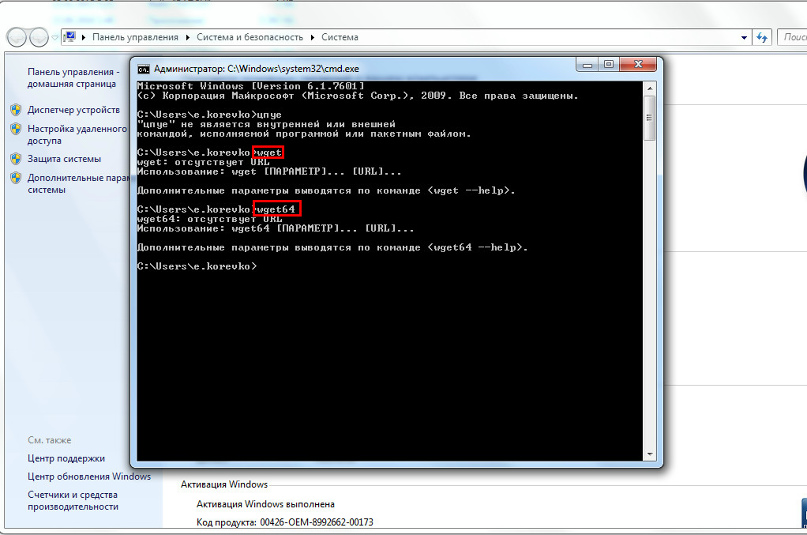
Проверяем работоспособность wget: для этого набираем в строке wget, жмём enter, потом wget64, жмём enter. Если вы получили отклик и всё так же, как на скрине, значит всё сделано правильно:
Качаем ленд
Всё. Wget у нас установлен, настроен и работает исправно. Теперь прописываем в консоли вот такую команду: wget --page-requisites http://адрес_сайта.ру. Жмём Enter и сайт начинает скачиваться:
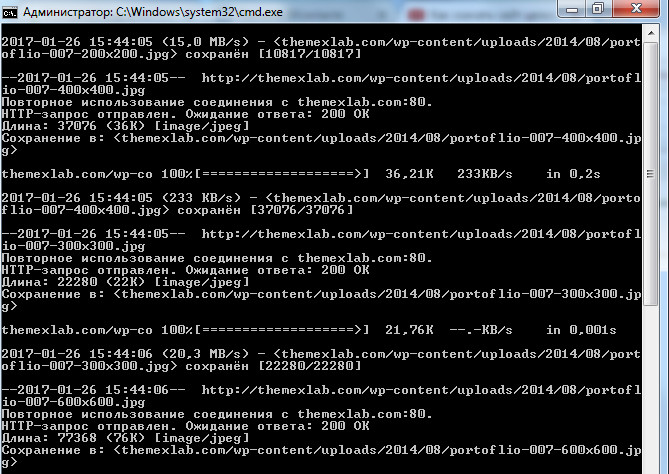
Теперь немного по самой команде:
wget - это вызов самой программы, собственно говоря
--page-requisites - этот параметр отвечает за то, чтобы все реквизиты сайта были скачаны (css файлы, шрифты, картинки и т.д.)
Если вы качаете не одностраничник, а сайт из нескольких страниц - добавляем -r -l 10, чтобы получилось wget --page-requisites -r -l 10 http://адрес_сайта.ру, где -r даёт команду качать и внутренние страницы, а -l 10 - это уровень вложенности.
Полный список команд можно найти без особых усилий в том же гугле по запросу команды wget.
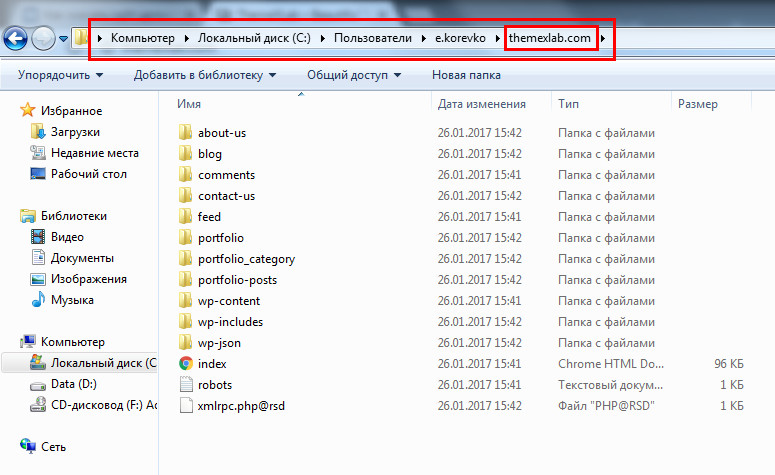
Выкачанный сайт находится в папке вашего пользователя:
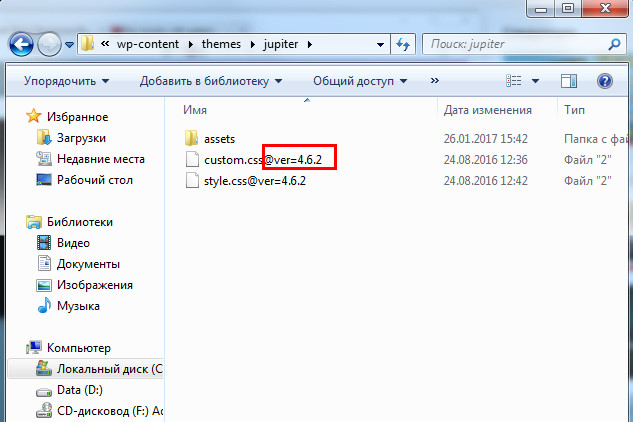
Теперь пробегаемся по всем папкам нашего сайта и, если видим какие-то файлы, в названиях которых присутствуют @какие-то кракозябы, выравниваем эти названия (т.е. просто удаляем всю эту хрень, начиная с @)
Вот и всё. Надеемся, этот материал вам пригодится не для варварских целей, а исключительно для самообразования, чтобы пощупать интересный сайт изнутри и понять, как он устроен ;-)
Вам была полезна эта статья?
0
0
Похожие статьи