
20 апреля 2026
TADA от Hume AI: обзор новой текстово-акустической модели синтеза речи
499
В последний год ИИ-голоса стали использовать везде: в рекламе, в видео, в автоматических обзвонах и даже внутри продуктов. Но с качеством до сих пор беда — то голос звучит неестественно, то модель пропускает куски текста, то на длинных фрагментах начинаются сбои.
Hume AI выпустила TADA — модель синтеза речи, в которой обещают решить эти проблемы за счет другой архитектуры. Главное отличие в том, что текст и звук синхронизируются по-новому, почти без галлюцинаций и с точным воспроизведением написанного сценария.
Рассказываем, что на самом деле изменилось, дает ли это преимущество перед ElevenLabs и где TADA действительно лучше, а где пока не дотягивает.
- Что такое TADA и в чем суть технологии
- Ключевые характеристики модели
- Возможности и функции
- Сравнение TADA с ElevenLabs
- Стоит ли тестировать TADA
Что такое TADA и в чем суть технологии
Большинство TTS-моделей работают так: текст превращается в последовательность токенов, из которых нейросеть пытается собрать звук. Проблема в том, что текст и звук идут с разной скоростью. На одну секунду текста приходится 2–3 токена, а на секунду звука — 12,5–75 акустических кадров. Разница выходит примерно в 10–25 раз.
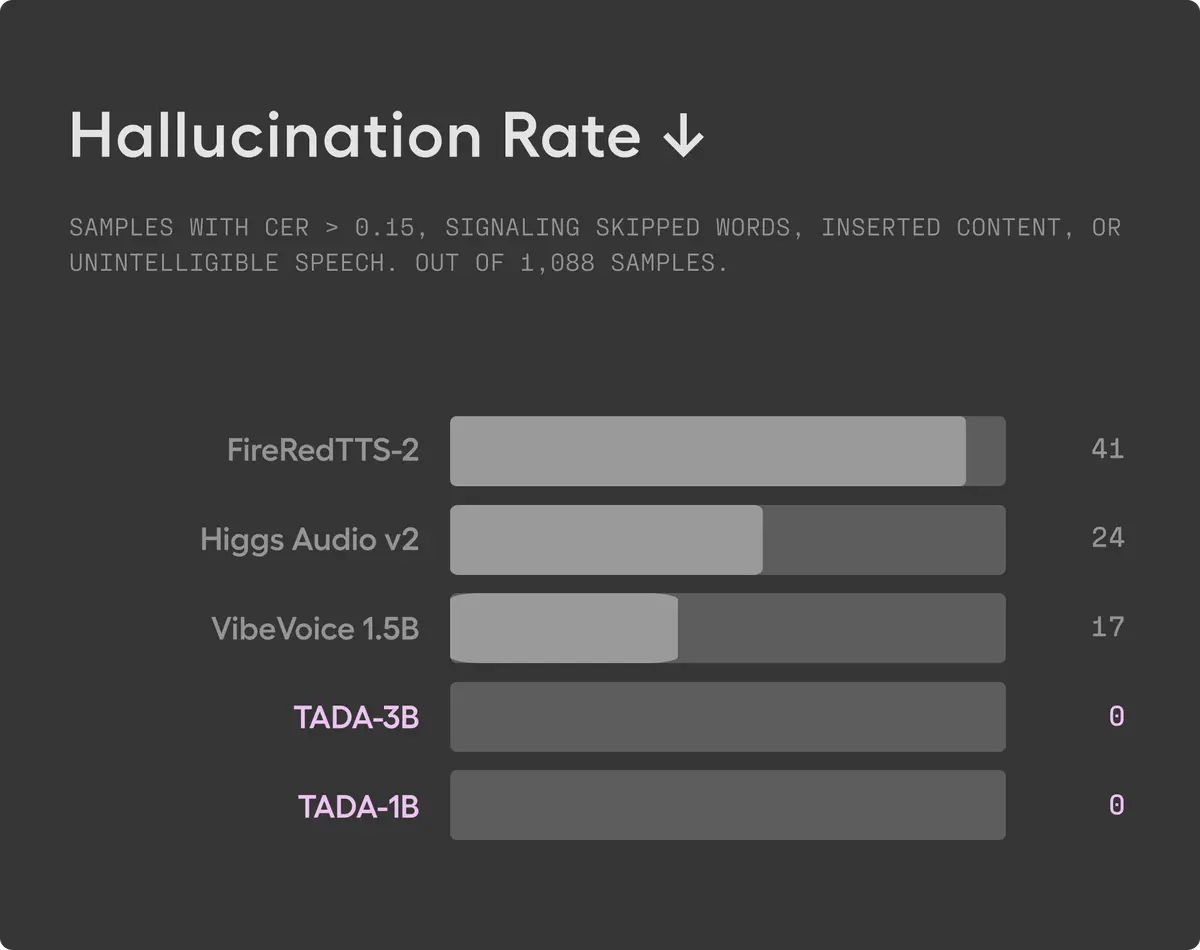
В результате такая модель вынуждена жонглировать потоками разной длины. Отсюда и глюки: то слово пропустит, то вставит лишнее, то на длинных фрагментах подведет. По исследованиям Hume AI, у FireRedTTS-2 на 1000 тестовых образцов было 41 искажение, у Higgs Audio V2 — 24, у VibeVoice — 17.
TADA использует архитектуру Text-Acoustic Dual Alignment, отсюда и название. Вместо того чтобы пытаться склеить текст и звук из разных потоков, модель синхронизирует их один к одному: один текстовый токен равен одному непрерывному акустическому вектору. LLM на каждом своем шаге выдает одновременно и следующий фрагмент текста, и соответствующий ему фрагмент звука.
Ключевые характеристики модели
Hume AI накидала в пресс-релизе много цифр и умных слов: RTF 0,09, контекст 700 секунд, ноль галлюцинаций. Звучит круто, что это значит, разбираем по пунктам.
Отсутствие галлюцинаций. По данным компании, в более чем 1000 тестовых образцов из набора LibriTTSR модель не допустила ни одной ошибки на уровне символов с порогом CER выше 0,15. При 1:1-синхронизации модель просто не может вставить или пропустить слово. Официальные данные Hume AI подтверждают, что на всех 1000+ образцах TADA допустила ноль галлюцинаций.
Скорость 0,09 RTF. RTF (Real Time Factor) показывает, сколько секунд нужно модели, чтобы сгенерировать одну секунду аудио. 0,09 означает, что 10 секунд речи создаются меньше чем за секунду. Для сравнения: XTTS-v2 работает на 0,19 RTF, FireRedTTS-2 — на 0,76. По данным создателей, TADA в 5+ раз быстрее сопоставимых LLM-решений. При этом она потребляет всего 2–3 вычислительных кадра на секунду аудио против 12,5–75 у классических подходов.
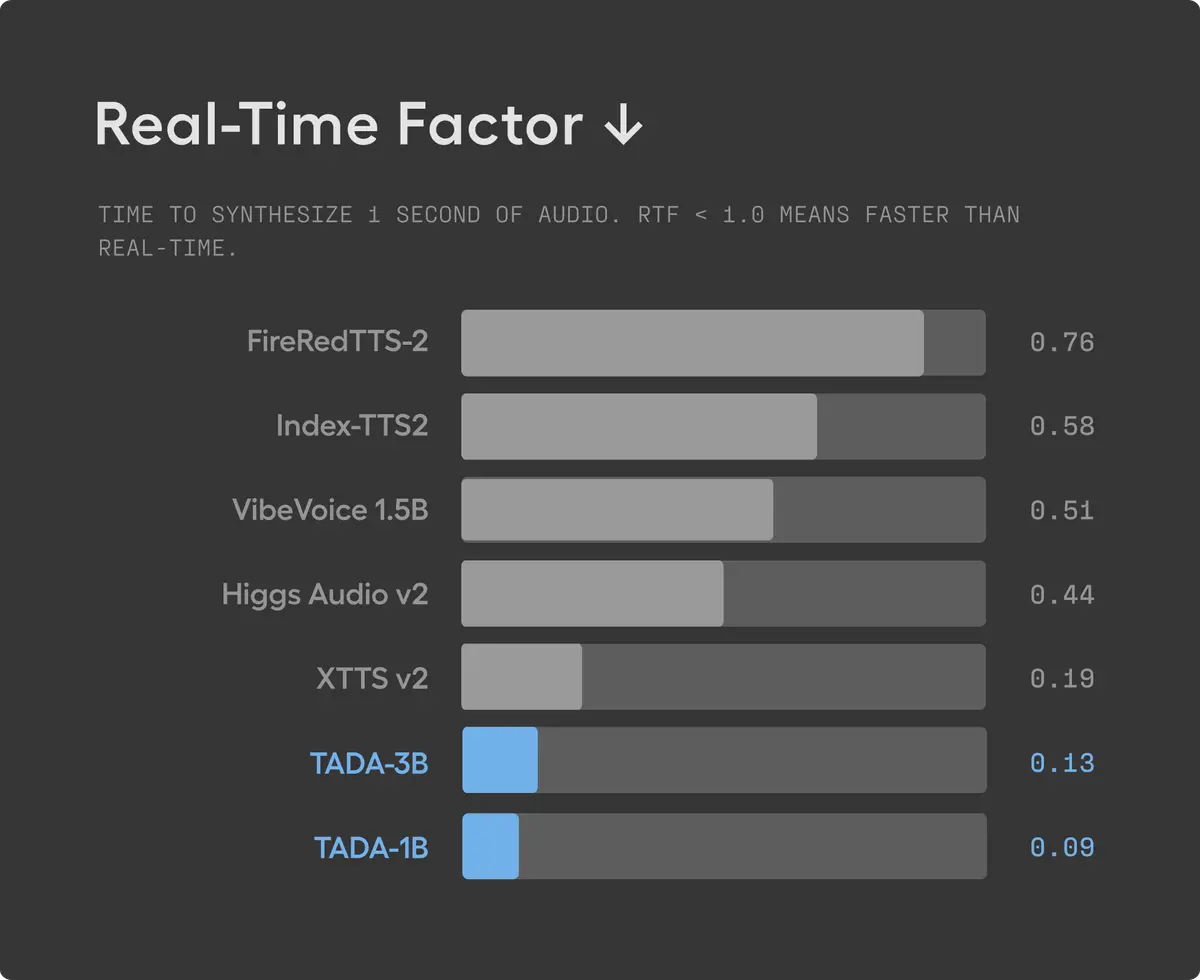
Скорость генерации и низкое потребление ресурсов позволяют тестировать десятки вариантов озвучки за час. Вместо того чтобы ждать по 20–30 секунд на каждую генерацию и платить за облачные вычисления, вы можете быстро собирать связки, экономя бюджет.
Длинный контекст. Модель использует контекстное окно в 2048 токенов. В обычных TTS этого хватает примерно на 70 секунд аудио. TADA упаковывает в то же окно до 700 секунд — почти 12 минут непрерывной речи. За счет синхронной токенизации модель тратит в 10 раз меньше токенов на секунду звука, чем конкуренты.
Вы можете озвучивать целиком вебинар, длинный ролик или подробный обзор продукта без резки на куски. Если вы работаете с нишами, где важна непрерывность восприятия без склейки, TADA может давать ровное и естественное звучание.
Возможности и функции
Разбираем фишки модели, которые могут пригодиться в ежедневной работе.
Синхронная транскрипция. Модель может параллельно отдавать текстовую расшифровку того, что произносит. То есть на одном прогоне вы можете одновременно получить готовые аудио и субтитры. Экономия времени на монтаже и минимизация ошибок при сборке креатива.
Разговорное аудио. Архитектура TADA в теории позволяет работать с очередностью реплик, прерываниями и динамикой с нескольких говорящих. Это может быть полезно для диалогов, интервью или подкастов с двумя ведущими, так как голоса не будут сливаться и звучать однообразно. Но на практике для сложных сценариев потребуется дополнительная настройка.
Эмоциональное воспроизведение. Модель обучена на детализированных аннотациях с широким спектром выразительной речи. Можно передать не только текст, но и эмоцию, например, радость, удивление, раздражение, спокойствие. В человеческих тестах на датасете EARS модель получила 3,78 из 5 за естественность и 4,18 за схожесть с реальным диктором.
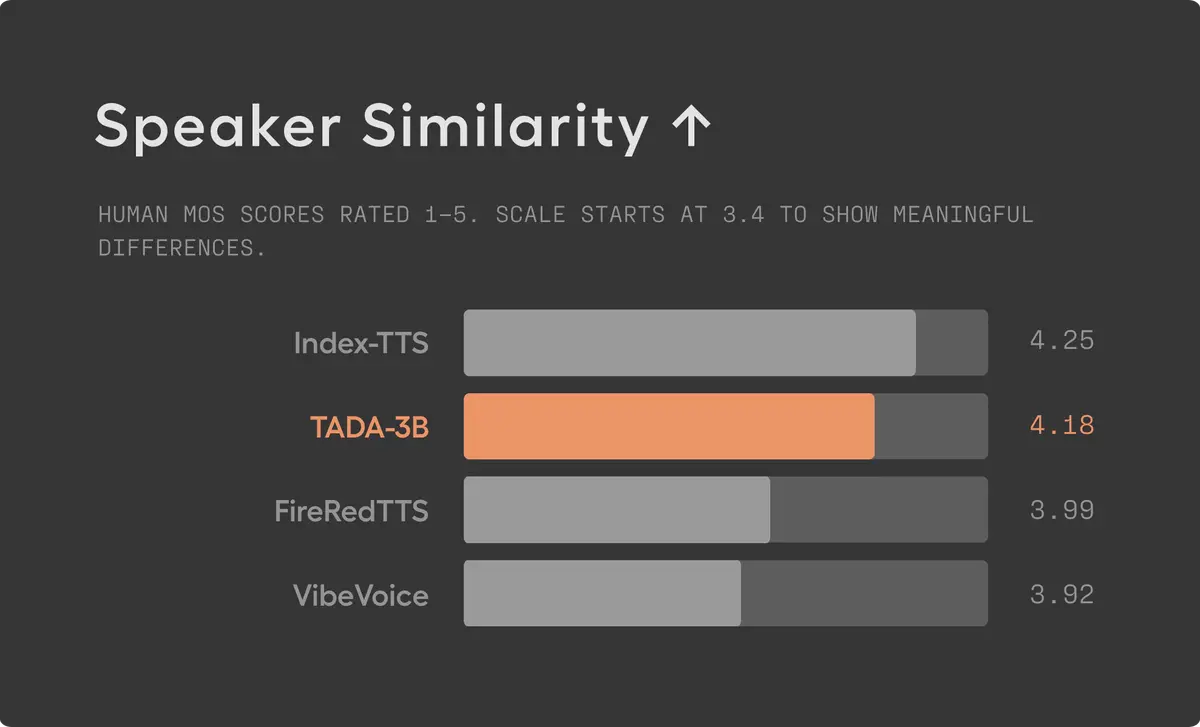
По общим оценкам TADA заняла второе место, обогнав несколько систем, обученных на заметно больших объемах данных.
Там, где важнее скорость и точность, качества TADA будет достаточно. Для премиальных проектов, где тон и эмоциональная окраска критичны, ElevenLabs пока остается в приоритете.
Многоязычное аудио. TADA поддерживает 10 языков: английский, чаморро, итальянский, арабский, испанский, французский, немецкий, японский, польский и португальский. Модель обучена на записях носителей с учетом диалектов. Версия 3B на Hugging Face идет с русским языком.
Можно генерировать озвучки на нескольких языках без переключения между инструментами. Единый пайплайн для локализации позволит экономить время и деньги.
Реализм голоса. Модель хорошо работает с интонацией, темпом и выразительным диапазоном. Речь не звучит роботизированно — есть паузы, ускорения, замедления, логические ударения.
Специфика по предметной области. Создатели TADA позиционируют модель как подходящую для отраслей с высокими требованиями к надежности, например, для здравоохранения, образования и финансов. Благодаря точной синхронизации текста и звука и отсутствию галлюцинаций инструмент может быть полезен там, где ошибки недопустимы. Для медицинских терминов может говорить спокойно и четко, для обучающих роликов — бодрее и с пояснительными интонациями.
В нишах, где важна тональность, это помогает снизить отторжение у пользователя. Ролик с живым голосом, который говорит в нужном ключе, получает больше доверия.
Специфические задачи. TADA подходит для диалогов с ассистентами, поддержки, репетиторства и исследований. Может работать в режиме «вопрос-ответ» и поддерживать множество функций. Для этого нужна дополнительная тонкая настройка, но базовая архитектура это позволяет.
Если вы делаете интерактивных ботов, голосовые опросы или прогревающие мини-диалоги в мессенджерах, TADA может дать базу, которую можно дообучить под конкретный сценарий. Не надо собирать решение из пяти разных API.
TADA выпущена по двум разным лицензиям: код открыт под MIT, а веса моделей распространяются под лицензией Llama 3.2 Community License. Перед запуском нужно запросить доступ к моделям Llama 3.2 на Hugging Face и принять условия лицензии.
Доступны две версии: 1B, которая работает только на английском, и 3B-ML, которая поддерживает 10 языков. Код и веса выложены на GitHub и Hugging Face. Есть и онлайн-демо, где можно попробовать модель без установки.
Для массовых задач, где нужна скорость и точность, TADA закрывает потребности с запасом. Для проектов, где голос будет лицом бренда, лучше пока присматриваться. Главное, что все это доступно по открытой лицензии.
Сравнение TADA с ElevenLabs
Сравнивать ElevenLabs и TADA сложно, потому что это продукты разного уровня. Первый сервис — зрелая коммерческая платформа с широкими возможностями и проверенным качеством, а продукт от Hume AI — это молодой open-source инструмент. Кстати, мы делали подробный обзор ElevenLabs, где рассказали про основные функции, тарифы и выделили плюсы и минусы.
Мы протестировали обе модели на реальных задачах: озвучивали рекламные креативы и технические тексты. И вот что выяснили.
- Качество и естественность речи.
ElevenLabs по этому параметру остается лидером. Их последняя модель Eleven v3 дает очень выразительный и живой голос, который сложно отличить от реального диктора. Это проверенный инструмент, который годами доводили до ума.
TADA звучит скромнее. В тестах естественность ее голоса оценили в 3,78 балла из 5. Для открытой модели это достойно, но до ElevenLabs пока далековато. Голос TADA иногда звучит плоско, без той эмоциональной глубины, которую дает ElevenLabs.
По нашим тестам ElevenLabs по качеству и естественности речи на шаг впереди новичка. Благодаря большому выбору голосов и ритмов, его легче настроить под любую задачу.
- Точность воспроизведения текста.
Компания Hume AI заявляет об отсутствии галлюцинаций. В тестах на датасете LibriTTSR модель не допустила ни одной ошибки, то есть не было ни пропущенных слов, ни лишних вставок, ни искажений. Порог качества — CER выше 0,15, это значит, что TADA практически не ошибается на коротких и средних текстах. Плюс архитектура Text-Acoustic Dual Alignment с синхронизацией 1:1 гарантирует точность на уровне структуры.
У ElevenLabs иной подход к тестированию и метрикам. В ноябре 2025 года компания выпустила модель Eleven v3. По внутренним тестам, охватывающим 27 категорий на 8 языках, процент ошибок при обработке чисел, символов и технических обозначений снизился на 68% — с 15,3 до 4,9%.
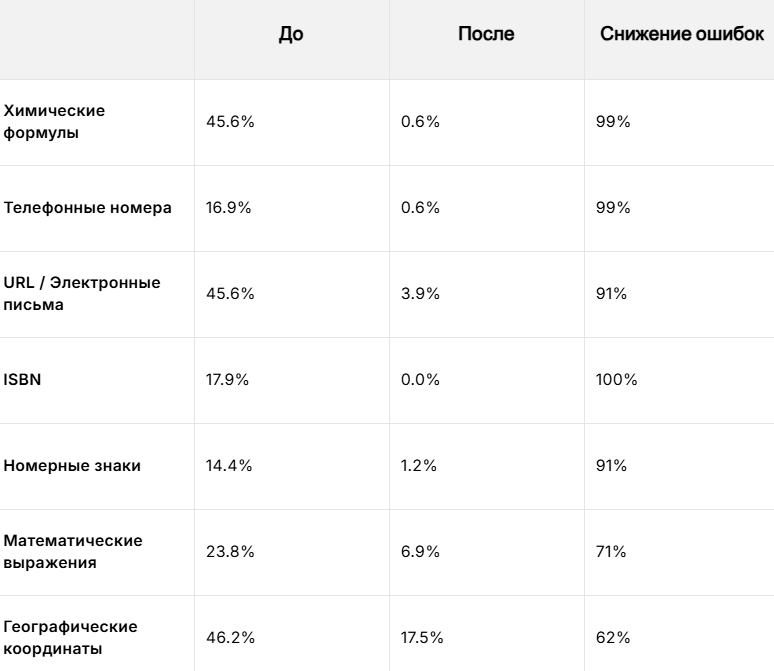
Мы опробовали обе модели на текстах с числами, аббревиатурами и англицизмами. По нашим экспериментам, сервисы хорошо справились на коротких фрагментах. И ElevenLabs, и TADA допускают ошибки при обработке аббревиатур и чтении англицизмов на длинных текстах.
- Скорость генерации.
По данным Hume AI TADA генерирует речь в пять раз быстрее аналогичных систем. Ее показатель RTF — 0,09. Это значит, что 10 секунд речи создаются меньше чем за секунду. Для массовой генерации креативов это серьезное преимущество.
У ElevenLabs есть Flash v2.5 с задержкой первого аудиокадра 75 мс, что критично для живых диалогов и интерактива.
У сервисов разные метрики скорости, поэтому сравнивать их в этом случае некорректно. TADA быстрее генерирует готовый файл, а ElevenLabs быстрее отдает первый звук. То есть первый инструмент будет полезен для массовой генерации креативов, а второй — для живых и реалистичных диалогов.
- Гибкость настройки и голоса.
По этому параметру ElevenLabs вне конкуренции. У них огромная библиотека голосов на 70+ языков, клонирование по короткому семплу, API для интеграции, детальная настройка эмоций и интонаций.
У TADA выбор голосов ограничен, полноценного клонирования нет, а экосистема вокруг модели только формируется.
- Длинный контекст.
По заявлениям создателей TADA поддерживает до 700 секунд аудио за один запуск, работая в окне из 2048 токенов. Обычные системы на том же бюджете выдают всего 70 секунд. Для озвучки вебинаров, аудиокниг и длинных видео это огромный плюс — не нужно резать текст на куски.
ElevenLabs на длинных текстах тоже работает стабильно, максимальная длина текста, которую вы можете генерировать — 5000 символов. В бесплатной версии есть ограничение в 2000 символов.
Наши тесты показали, что обе модели хорошо справляются с текстами средней длины.
Цена и доступность. TADA — open-source проект с раздельным лицензированием, и это важно учитывать перед коммерческим использованием.
Код на GitHub распространяется под лицензией MIT. Это значит, что вы можете делать с программной частью что угодно, например, модифицировать и использовать в коммерческих проектах.
Веса моделей распространяются под Llama 3.2 Community License — той же, что и у базовой Llama 3.2 от Meta*, на которой построена TADA. Она тоже разрешает коммерческое использование, но с определенными условиями, например, нельзя использовать модель для улучшения других LLM без разрешения Meta. Полный текст лицензии стоит проверить отдельно.
ElevenLabs — платный сервис с тарифами от $6 до $990 в месяц.
Если у вас большие объемы озвучки и бюджет ограничен, TADA окупает себя моментально.
Итоги сравнения. ElevenLabs остается выбором для премиум-проектов, где голос должен звучать максимально естественно, важна тонкая настройка эмоций и богатый выбор голосов.
TADA — отличная альтернатива для генерации креативов, локализации на 10 языках, технических текстов.
Стоит ли тестировать TADA
Если вы тестируете десятки связок в день или озвучиваете длинные видео, TADA вас выручит. На данный момент она бесплатна, не врет в цифрах и не заставляет ждать результата по пять минут.
Если важна тонкая эмоциональная окраска и уникальный тембр, ElevenLabs все еще незаменим. Сервис платный, зато дает то, что TADA пока не умеет: живую интонацию, огромный выбор голосов и готовую инфраструктуру.
TADA можно запустить за пять минут в демо и сразу понять, подходит она под ваши задачи или нет.
* Принадлежит компании Meta, признанной экстремистской и запрещенной на территории РФ.
Вам была полезна эта статья?
2
0
Интернет-медиа про маркетинг и арбитраж трафика
Похожие статьи